

Convolutional neural networks(CNN)
A convolutional neural network (CNN) is a type of artificial neural network used primarily for image recognition and processing, due to its ability to

What is CNN?
Convolutional neural networks (CNN/ConvNet) are a kind of deep neural network used most frequently to interpret visual data in deep learning. Normally, matrix multiplications come to mind when we think of a neural network, but that is not the case with ConvNet. It makes use of a unique method called convolution. Convolution is a mathematical procedure that takes two functions and creates a third function that explains how the form of one is changed by the other in mathematics.
Flow of CNN
Convolutional Neural Network or CNN is a type of artificial neural network, which is widely used for image/object recognition and classification. Deep Learning thus recognizes objects in an image by using a CNN.
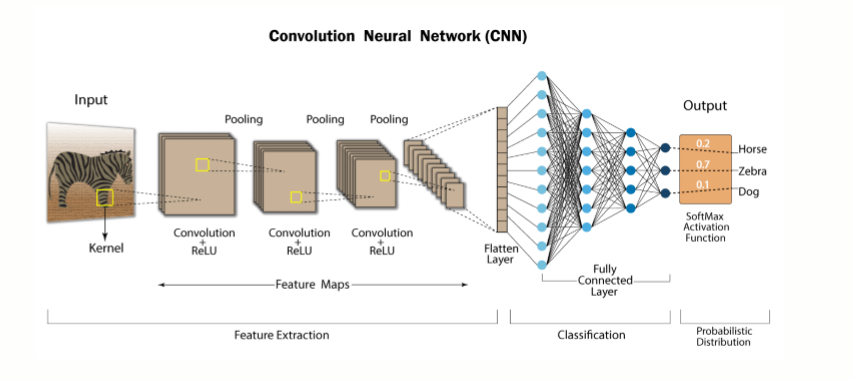
Layers
Convolution
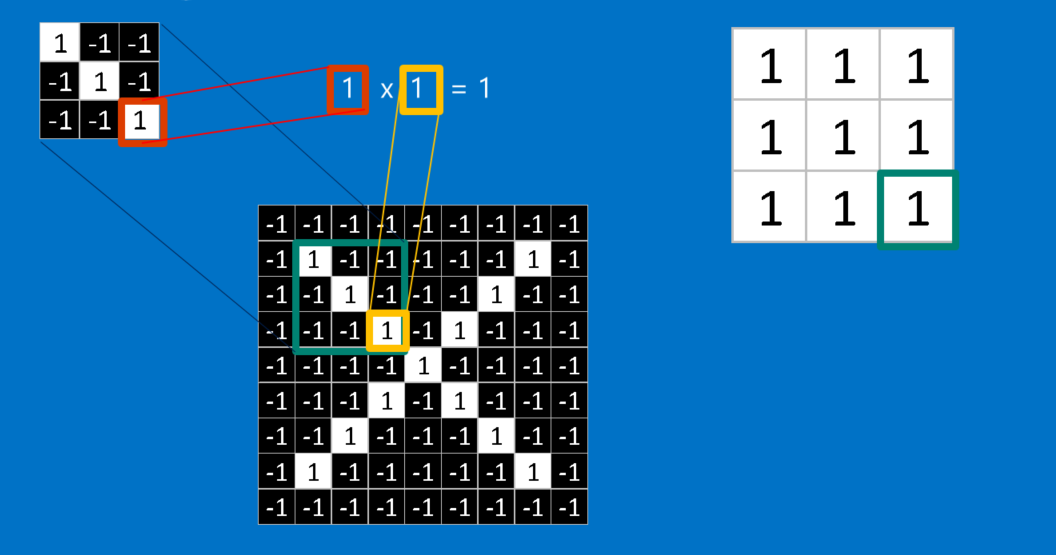
CNN tests these traits everywhere and in every conceivable place because it is uncertain where they will match in a fresh image. We turn it into a filter by computing the match to a feature over the entire picture. Convolutional Neural Networks get their name from the convolutional math we utilise to do this.
Convolution's arithmetic is simple enough for a sixth-grader to understand. Simply multiply each pixel in the feature by the value of the corresponding pixel in the picture to determine how well a feature matches a region of the image. Divide the total number of pixels in the feature by the sum of the replies. When both pixels have a value of 1 or white, 1 1 equals 1. If they're both black, (-1) (-1) = 1. In either case, a 1 is produced for each matched pixel. Any discrepancy is also a -1. When all the pixels in a feature match, their sum is 1, and their number is divided by the total number of pixels. Similar to this, the response is a -1 if none of the pixels in a feature match the picture patch.
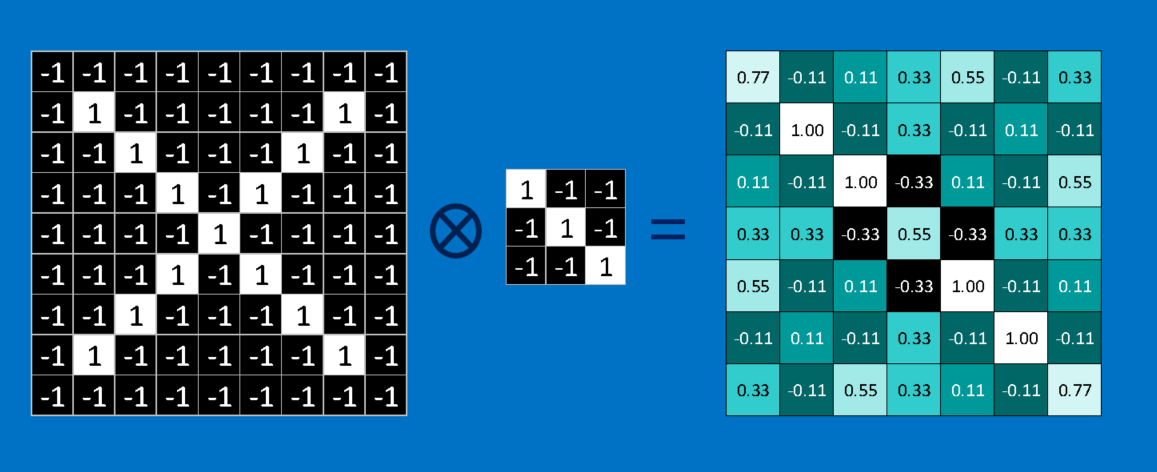
We continue this procedure in order to finish our convolution, aligning the feature with each potential picture patch. On the basis of the location of each patch in the picture, we may take the result of each convolution and create a new two-dimensional array from it. The image we started with has been filtered to create this map of matches. It shows the location of the feature inside the picture on a map. Strong matches are shown by values close to 1, strong matches for the photographic negative of our feature are indicated by values close to -1, and no matches of any kind are indicated by values close to zero.

The complete convolution procedure must then be repeated for each of the additional characteristics. A collection of filtered photos, one for each of our filters, is the outcome. Conveying this entire set of convolution processes as a single processing step is practical. This is referred recognised as a convolution layer in CNNs, indicating that further layers will be added to it shortly.
It's understandable how CNNs gained a reputation for being computation hogs. The number of additions, multiplications, and divisions can pile up quickly even though we can draw our CNN on the back of a napkin. They scale linearly with the number of pixels in the picture, the number of pixels in each feature, and the total number of features, to use mathematical terminology. With so many contributing components, it's simple to multiply this issue by millions without breaking a sweat. It should come as no surprise that chip makers are now producing specialist processors in an effort to keep up with CNN's needs.
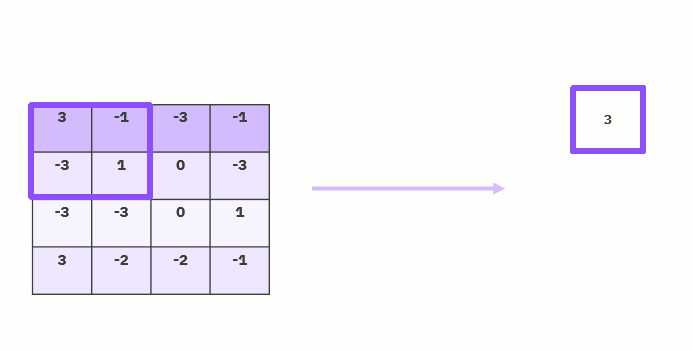
Pooling Layer
The size of the feature maps is reduced by pooling layers. As a result, it lessens the quantity of network computation and the number of parameters that must be learned. The feature map created by a convolution layer's feature pooling layer summarises the features that are present in a certain area. Therefore, instead of precisely positioned features produced by the convolution layer, additional actions are conducted on summarised features. As a result, the model is more resistant to changes in the features' positions in the input picture.
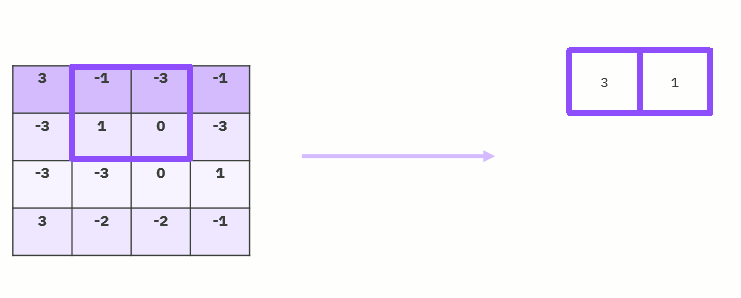
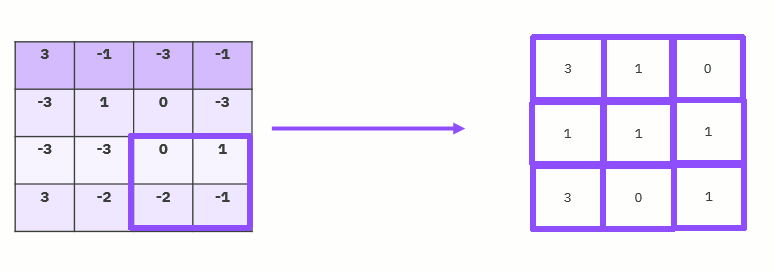
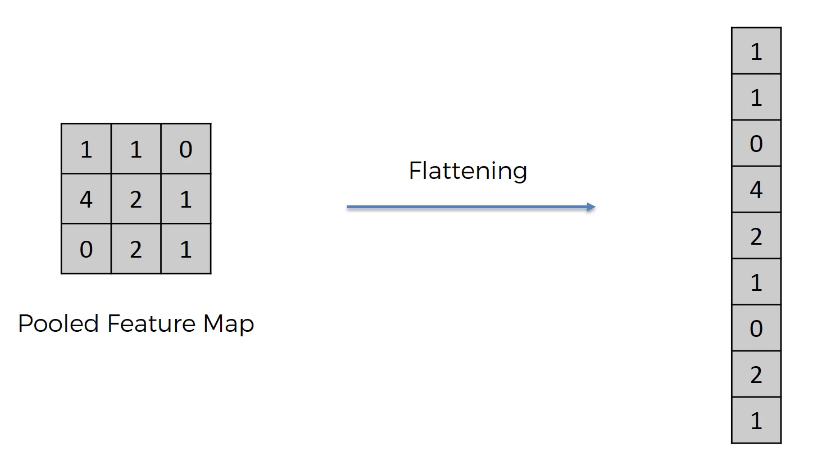
Flattening Layer
A flatter layer is a pleasantly straightforward phase in the construction of a convolutional neural network. It entails converting the pooled feature map produced during the pooling process into a one-dimensional vector. Here is an illustration of how this procedure appears:
Fully connected layer
The entire connection stage entails chaining an artificial neural network onto our pre-existing convolutional neural network, as you can probably surmise from the previous part. The artificial neural network's hidden layer is replaced with a particular kind of hidden layer known as a fully connected layer in this stage, which is why it is known as the full connection step. The neurons in a layer that is totally connected are all linked together, as the name suggests. Here is an illustration of an artificial neural network's completely linked layer in visual form:
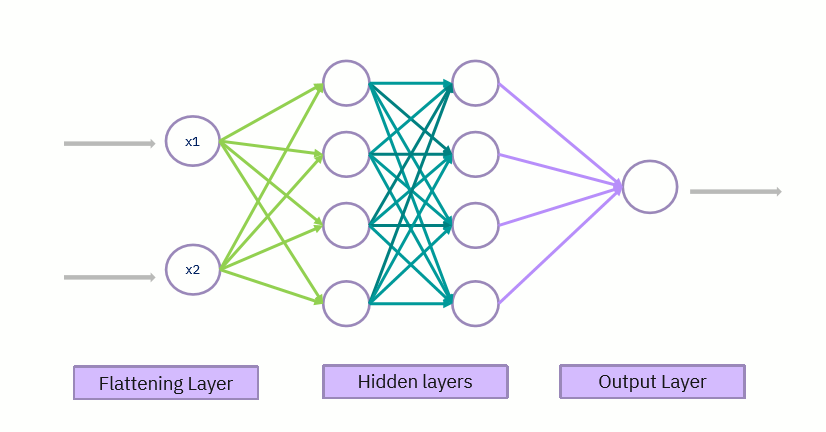
In a convolutional neural network, the fully connected layer's job is to identify certain characteristics in an image. A specific feature that could be present in a picture is associated with each neuron in the fully connected layer. The likelihood that the feature is present in the picture is represented by the value that the neuron transmits to the following layer. Convolutional neural network and artificial neural network both come to an end at the same time. To put it another way, CNN's artificial neural network predicts what is there in the image that it is attempting to recognise!
See you soon
Turn on your notifications and stay in touch with us to learn about new ideas. Share this blog with your friends and family... I will see you in the next blog. Thank you all.



