

Reinforcement Learning
Reinforcement learning is a machine learning training method based on rewarding desired behaviours and/or punishing undesired ones.

Recap
Previous blog, We learned about KNN(K-Nearest Neighbor). KNN is a classification algorithm based on classifying data points by determining similarity among existing data points. Now we are going to learn about self-learning algorithms.
Reinforcement Learning
As a machine learning technique, reinforcement learning concerns the appropriate actions that software agents should do in a given environment. The deep learning method includes reinforcement learning, which enables you to maximise a percentage of the cumulative reward.
Algorithm
Three approaches to implementing a Reinforcement Learning algorithm:
- Value-Based
- Policy-Based
- Model Based
1. Value-Based:
Developers should aim to maximize the value function V in a value-based reinforcement learning strategy (s). With this approach, the agency anticipates that the current policy-covered states will eventually return.
2. Policy-Based:
In a policy-based RL technique, developers work to create a policy where every action you do now helps you reap the most rewards tomorrow.
Two policy-Based methods:-
Deterministic=> The policy π results in the same action for any state.
Stochastic=> The probability of any action is defined.
3. Model-Based:
For each environment in this Reinforcement Learning technique, a virtual model must be built. The agent gains the necessary skills to function in that environment.
Types of Reinforcement Learning
Positive Reinforcement:
It is described as an occurrence that results from a particular action. It strengthens and repeats the behaviour more frequently, which has a favourable effect on the agent's action.
This kind of reinforcement enables you to achieve your full potential and maintain change over a longer time frame. However, excessive reinforcement may result in state over-optimization, which might have an impact on the outcomes.
Negative Reinforcement:
A negative condition that should have been halted or avoided might reinforce a behaviour. This is known as "negative reinforcement." You can use it to specify the minimum performance standard. The disadvantage of this approach is that it just offers enough to satisfy the minimum behaviour.
Markov Decision Process
The reinforcement learning issues are formalised using the Markov Decision Process, or MDP. If the environment is entirely observable, a Markov Process can be used to model the environment's dynamic. In MDP, the agent continuously engages with the environment and takes action. The environment reacts to each action and creates a new state.
The RL environment is described using MDP, and practically all RL problems may be formalised using MDP.
MDP has 4 parameters:
- set of finite States S
- set of finite Actions A
- Rewards are obtained following the change from state S to state S' as a result of action a.
- Probability Pa
Q-Learning
A well-liked model-free reinforcement learning algorithm built on the Bellman equation is Q-learning. Learning the policy that can tell the agent what actions to perform to maximize the reward under what conditions is the basic goal of Q-learning. It is an off-policy RL that looks for the best course of action given the circumstances. In Q-learning, the agent's objective is to maximize Q's value. The Bellman equation can be used to determine the worth of Q-learning. Consider the following Bellman equation:
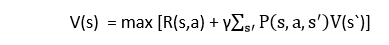
Process:
Temporal difference learning is accomplished using the Off policy RL algorithm Q-learning. Comparing temporally successive predictions are done using temporal difference learning methods. It learns the value function Q (S, a), which denotes the optimal course of action for a given state "s."
Applications of Reinforcement Learning
- Robotics
- Business strategy planning
- Aircraft control and robot motion control, etc..
Conclusion
I anticipate that this article will clearly explain the reinforcement learning algorithm. To ascertain more about machine learning and to do working machine learning models, check out my machine learning series. If you have any questions or doubts, mention them in this article's comments section, and connect with me to learn more about machine learning.
Learning is an interesting habit..!




