


Classification is one of the classifications for supervised learning. The Classification algorithm is a Supervised Learning approach used to determine the category of new observations based on training data. Software in Classification learns from a given dataset or observations and then classifies additional observations into several classes or groups.
Instances include categorising an email as "spam" or "non-spam," and providing a diagnosis to a patient based on observable features (presence or absence of specific symptoms, etc.).
Means
A classifier is an algorithm that accomplishes classification, particularly in a concrete implementation. The word "classifier" can also refer to the mathematical function that translates input data into a category and is implemented by a classification algorithm.
Types
Classification is divided into two problems: binary classification and multiclass classification. Binary classification, a simpler problem, requires only two classes, whereas multi class classification involves assigning an item to one of the multiple classes. Because many classification methods have been created exclusively for binary classification, multiclass classification frequently requires the employment of multiple binary classifiers in parallel.
Models
The classification model can be divided into two categories:
Linear Models
Non-linear Models
Linear Models
This is achieved via a linear classifier, which makes a classification decision based on the value of a linear combination of the features. The characteristics of an object are also known as feature values, and they are often supplied to the computer in the form of a vector called a feature vector. Such classifiers perform well in real issues such as document classification and, more broadly, problems with numerous variables (features), achieving accuracy levels comparable to non-linear classifiers but requiring less time to train and utilise.
Non-Linear Models
The k-NN has properties of a Non-linear model and the outcome of k-NN classification is class membership. A plurality vote of its neighbours classifies an item, with the object allocated to the nearest cleanest class among its k nearest neighbours (k is a positive integer, typically small). If k = 1, the item is simply assigned to the class of the object's single nearest neighbour. Its applications include classification and regression. The input in both cases consists of the k closest training examples in a data collection.
Example:
Spam detection
Use Jupyter Notebook.
- Needed modules are imported
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib notebook
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.dummy import DummyClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import confusion_matrix
- Returns sparse feature matrix with an added feature.feature_to_add can also be a list of features.
def add_feature(X, feature_to_add):
from scipy.sparse import csr_matrix, hstack
return hstack([X, csr_matrix(feature_to_add).T], 'csr')
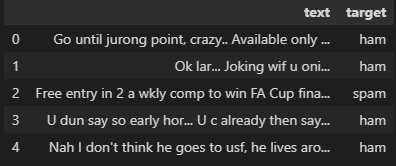
- The CSV dataset can be read by pandas.read_csv method.Read the dataset ' spam.csv ' to give an understanding to the system which is spam and which is not spam(ham). Use the dataFrame to print the data of spam.csv .
df = pd.read_csv('./spam.csv')
df.head()
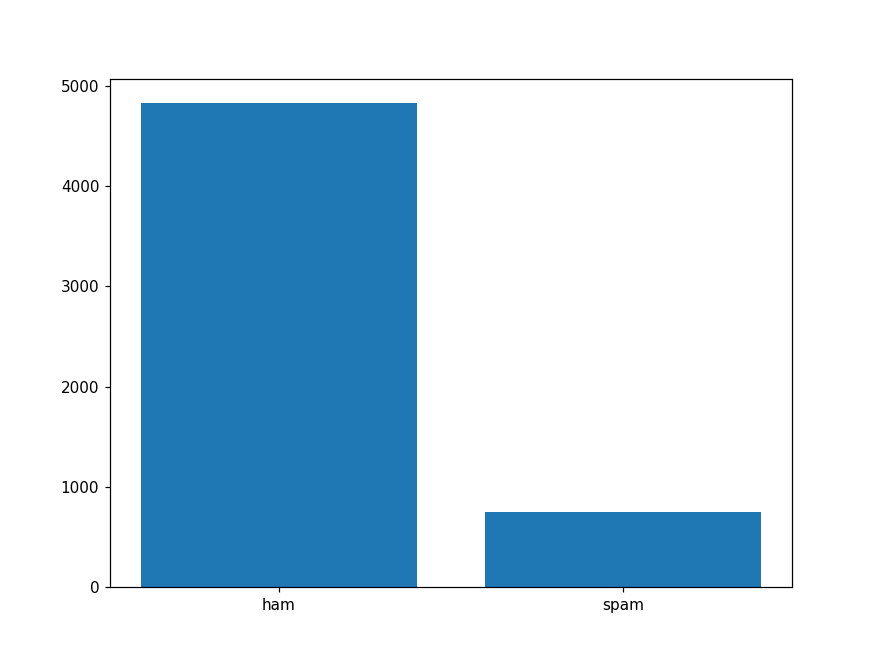
- Picture a graph of spam and ham
plt.figure(figsize=(8, 6))
x_axis = df['target'].unique()
y_axis = df['target'].value_counts()
plt.bar(x_axis, y_axis)
plt.show()
X = df['text']
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
X_train.shape, y_train.shape, X_test.shape, y_test.shape
// ((4457,), (4457,), (1115,), (1115,))
- we have split the data into a ratio of 8:2; training and test respectively. Then we have initialized a count vectorizer with the following parameters. Though you can merge with those to get even better results, keep in mind to not overfit your model.
vect = CountVectorizer(min_df=5, ngram_range=(2, 5), analyzer='char_wb')
vect.fit(X_train)
//CountVectorizer(analyzer='char_wb', min_df=5, ngram_range=(2, 5))
- we fitted and transformed the training and test data after initialising the vectorizer, and we added a few extra features to them. The overall length of the text, the total amount of numeric characters in the text, and the total number of words in the text are the new features.
X_train_vect = vect.transform(X_train)
X_train_vect = add_feature(X_train_vect, [len(x) for x in X_train])
X_train_vect = add_feature(X_train_vect, [sum(char.isnumeric() for char in x) for x in X_train])
X_train_vect = add_feature(X_train_vect, X_train.str.count('\W'))
X_test_vect = vect.transform(X_test)
X_test_vect = add_feature(X_test_vect, [len(x) for x in X_test])
X_test_vect = add_feature(X_test_vect, [sum(char.isnumeric() for char in x) for x in X_test])
X_test_vect = add_feature(X_test_vect, X_test.str.count('\W'))
- To obtain the baseline performance, we used a dummy classifier. It was fitted using training data and a prediction was generated with test data.
dummy_model = DummyClassifier()
dummy_model.fit(X_train_vect, y_train)
dummy_pred = dummy_model.predict(X_test_vect)
model = LogisticRegression(C=100, max_iter=1000)
model.fit(X_train_vect, y_train)
pred = model.predict(X_test_vect)
- A confusion matrix is used to evaluate both the Dummy and Logistic Regression models. We can observe that the Logistic Regression model performed significantly better than our Dummy model. However, it is not ideal, as identifying spam is a more precision-based challenge in my opinion. Therefore, there is still potential for development.
print('Dummy Classifier\n')
print(confusion_matrix(y_test, dummy_pred))
//Dummy Classifier
//[[958 0]
//[157 0]]
print('Logistic Regression\n')
print(confusion_matrix(y_test, pred))
//Logistic Regression
//[[955 3]
//[ 10 147]]
Spam Detection is one of the best examples of classification in supervised learning. Then we will learn other supervised learning types in the upcoming blog. Until connect with me and share this blog with your friends and colleagues!....💖.




