


Recap
Last Blog we have discussed Linear Regression with an exciting example Predicting Breast Cancer. From the example, we have created one model which predicts breast cancer using the dataset. Now let's see about Naive Bayes.
Naive Bayes
Naive Bayes is a classifier family that uses Bayes' theorem to calculate the probability of a result given a collection of circumstances. In other words, the conditional probabilities are reversed, allowing the query to be stated as a function of measurable variables.
The technique is straightforward, and the term "naive" has been applied not because these algorithms are restricted or inefficient. Still, because of a fundamental assumption about the causative components, we'll explore. Naive Bayes are multifunctional classifiers with various applications. nevertheless, their performance is especially strong in all instances where the likelihood of a class is influenced by the probabilities of certain causative components. Natural language processing is an excellent example, where a piece of text may be seen as a specific instance of a dictionary, and the relative frequencies of all terms offer enough information to infer a class membership. These ideas will be covered in later chapters. In this one, our examples will always be general in order to help the reader learn how to use naive Bayes in a variety of situations.
Bayes' theorem
Consider A and B, two probability occurrences. Using the product rule, we can link the marginal probabilities P(A) and P(B) with the conditional probabilities P(A|B) and P(B|A).
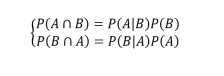
that the intersection is commutative, the first members are equal. so we can derive Bayes' theorem:
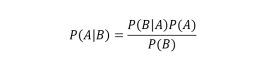
Naive Bayes classifiers
A naive Bayes classifier is called so because it's based on a naive condition, which implies the conditional independence of causes. This can seem very difficult to accept in many contexts where the probability of a particular feature is strictly correlated to another one.
For example, in spam filtering, a text shorter than 50 characters can increase the probability of the presence of an image, or if the domain has been already blacklisted for sending the same spam emails to million users, it's likely to find particular keywords.
Let's consider a dataset:
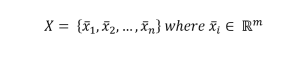
Every feature vector, for simplicity, will be represented as:
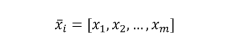
We need also a target dataset:
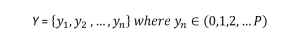
Here, each y can belong to one of P different classes. Considering Bayes' theorem under conditional independence, we can write:
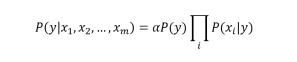
The values of the marginal Apriori probability P(y) and of the conditional probabilities P(xi|y) are obtained through a frequency count. therefore, given an input vector x, the predicted class is the one for which the a posteriori probability is maximum.
Example
Check Weather is good to play or Not.
Implemented in Jupyter Notebook. The modules used are pandas,sklearn and nlp to process the text data.
#NaiveBayes project (Weather Prediction)
#Required Modules
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.naive_bayes import GaussianNB
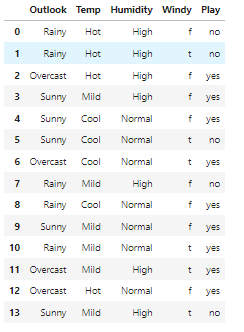
df = pd.read_csv("weather_dataset.csv")
df
#Encoding the strings to Numericals
outlook_at=LabelEncoder()
Temp_at=LabelEncoder()
Hum_at=LabelEncoder()
win_at=LabelEncoder()
#Dropping the target variable and make it is as newframe
inputs=df.drop('Play',axis='columns')
target=df['Play']
target

#Creating the new dataframe
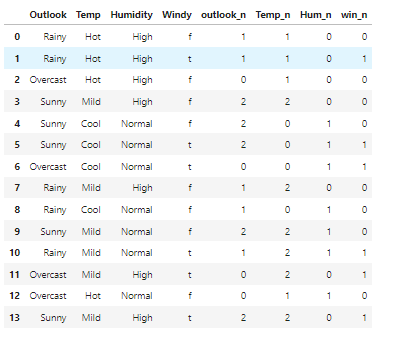
inputs['outlook_n']= outlook_at.fit_transform(inputs['Outlook'])
inputs['Temp_n']= outlook_at.fit_transform(inputs['Temp'])
inputs['Hum_n']= outlook_at.fit_transform(inputs['Humidity'])
inputs['win_n']= outlook_at.fit_transform(inputs['Windy'])
inputs
#Dropping the string values
inputs_n=inputs.drop(['Outlook','Temp','Humidity','Windy'],axis='columns')
inputs_n
#Applying the Gaussian naivebayes
classifier = GaussianNB()
classifier.fit(inputs_n,target)
//GaussianNB()
#85% accuracy
classifier.score(inputs_n,target)
//0.8571428571428571
#Prediction
classifier.predict([[0,0,0,1]])
//array(['yes'], dtype='<U3')
The Prediction return yes, which means the weather is good to play. We will learn new things in the upcoming blog until then connect with me and share it with your friends and colleagues!....💖.




